Follow along in Google Colab or Kaggle.
There are hundreds of Large Language Models available. This guide helps you find the right one for your app.
This guide assumes that you have some data to make the decision on (examples or past usage). If you
labelled your data, check this guide instead.
Introduction to custom benchmarks
There is no shortcut. You need to run a benchmark or an A/B test to be able to tell which model to use. This guide walks through the setup:- Send example prompts to a state-of-the-art model to establish a baseline with a Jupyter notebook.
- Use Narev Cloud to find a model that performs like the baseline with lower cost and better latency.
- Deploy the optimal model to production.
Why not use an LLM leaderboard instead?
LLM leaderboards show results from academic benchmarks. There are three reasons not to use academic benchmarks when making your decision on which model to use:- Academic benchmarks are a poor approximation of your app. The leaderboards show scores that LLMs get on standardized tests. The promise is that strong benchmark scores transfer to production, but this often fails. A 3-year-old model can match a current state-of-the-art model despite drastically different benchmark results.
- Academic benchmarks aren’t repeatable. Benchmark results vary depending on who runs them. For example, GPT-4’s score on the MMLU-Pro benchmark ranges from
72.6%to85.7%depending on the leaderboard. - People game academic benchmarks. For example, researchers document manipulation of Chatbot Arena in a major study by Singh et al. (2025). Data contamination is rampant (models that use benchmark questions in their training process). Read more about it in our docs on benchmarking.
Before you begin
To complete this guide, you’ll need:- A Narev account (sign up here) and a Narev API key (get one here)
- Python 3.8+ installed locally or access to Google Colab/Kaggle
- 50-100 example prompts representative of your production use case
- Basic familiarity with Python and Jupyter notebooks
- ~30 minutes to complete the setup and benchmarking
If you prefer not to use Python, you can upload prompts directly via the Narev dashboard or import from tracing
systems. See data source options.
Setting up your benchmark
Part 1: Create an A/B test endpoint on Narev platform
Create new application and select Live Test as your data source. You should get a URL that looks like this:Part 2: Open and prepare the environment
This guide uses a short Kaggle and Google Colab notebook to get started. It uses GSM8K benchmark data from HuggingFace. Start by importing libraries and setting credentials:The system prompt is very simple here. We can iterate on the system prompts in the Narev platform to optimize further.
gsm8k dataset. Here you should load the actual prompts that you would be using in your application.
Part 3: Send the requests to Narev
All that’s left to do here is sending the requests to Narev. We’ll select the state of the art model for this.Optimization in the Narev platform
Part 1: Select test Variants
When you head to the Platform -> Variants page, you should see an automatically created variant based on your request. Behind the scenes, the Narev platform took your requests to Gemini 3 Pro (defined as theSOURCE_OF_TRUTH) and created prompts that are now ready to run an A/B test on.
Deepseek-v3.2-Speciale is an alternative for the Gemini 3 Pro Preview. Then I looked for an alternative for the Deepseek model, and so on and so forth.
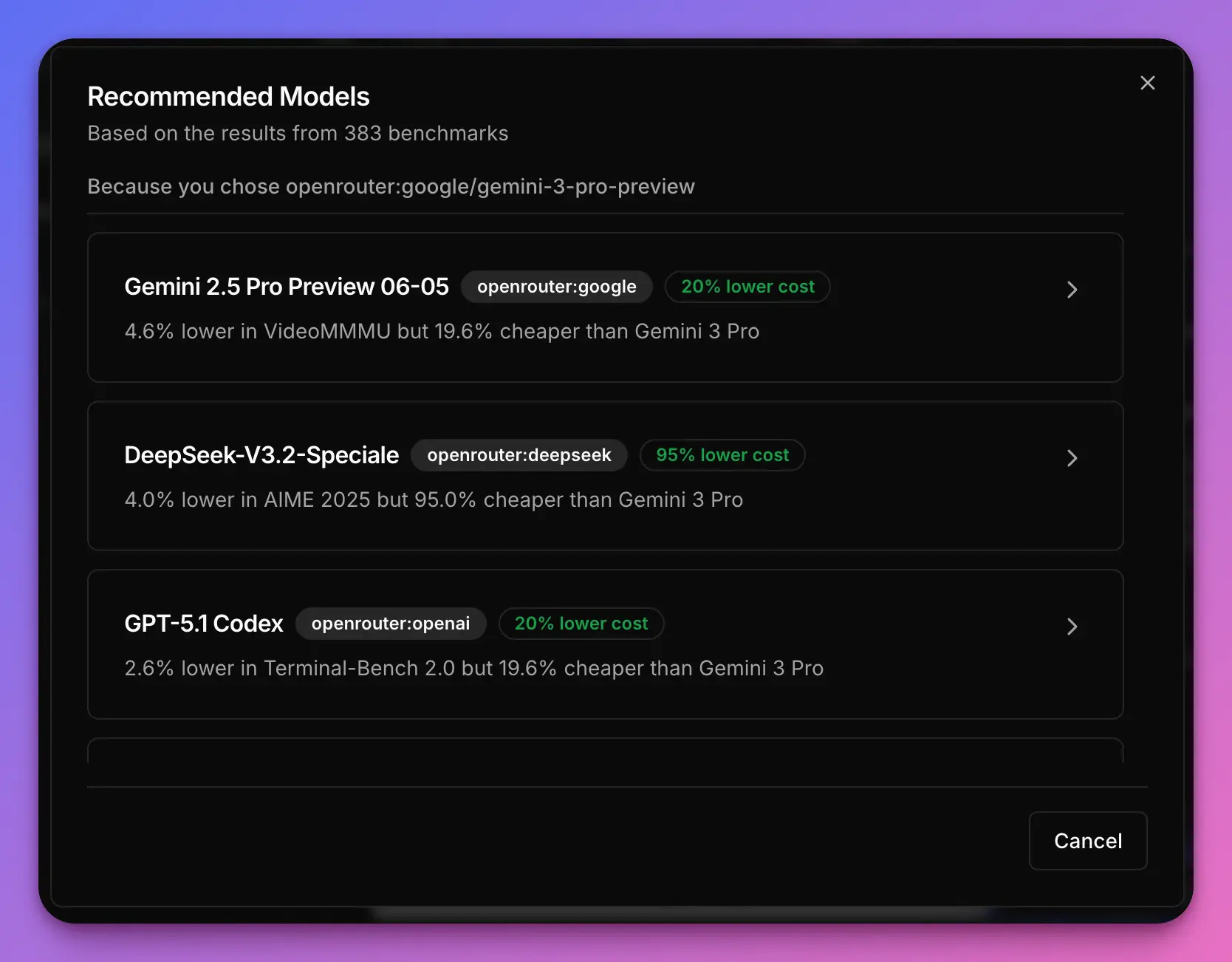
Narev’s recommendation engine takes into account the performance of over 400 models and recommends those that achieve
similar performance but offer significantly lower price or latency.
- Gemini 3 Pro Preview - our first model, tagged as state of the art,
- DeepSeek v3.2 Speciale - flagship model from the DeepSeek team
- GPT-5 Nano - recommended by Narev as a competitor performing in the benchmark similarly to the DeepSeek’s model
- Llama 3 70B Instruct - great open source model that I tried in many experiments in the past
- Ministral 3B - tiny, powerful model, from Narev’s recommendations
Part 2: Select the Source of Truth model and the Quality Metric
Since we don’t have labels of what the correct response is, we can rely on a proprietary State of Art model and treat it as the truth. In order to do that I’ve selected the model that I used in the notebooks - Gemini 3 Pro Preview.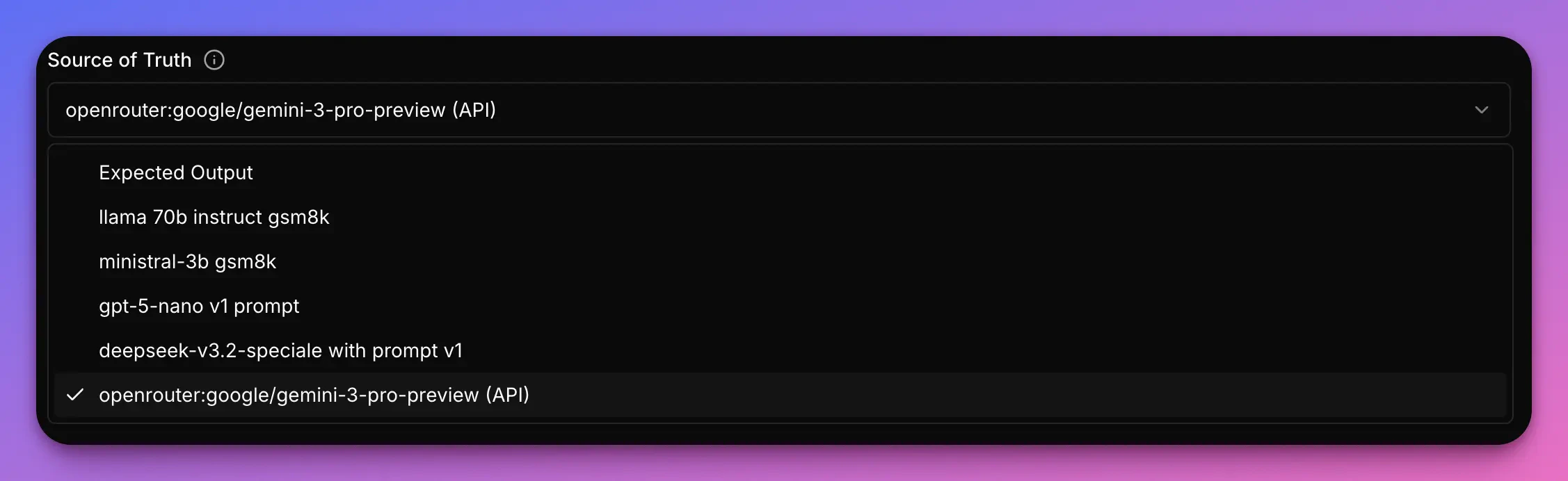
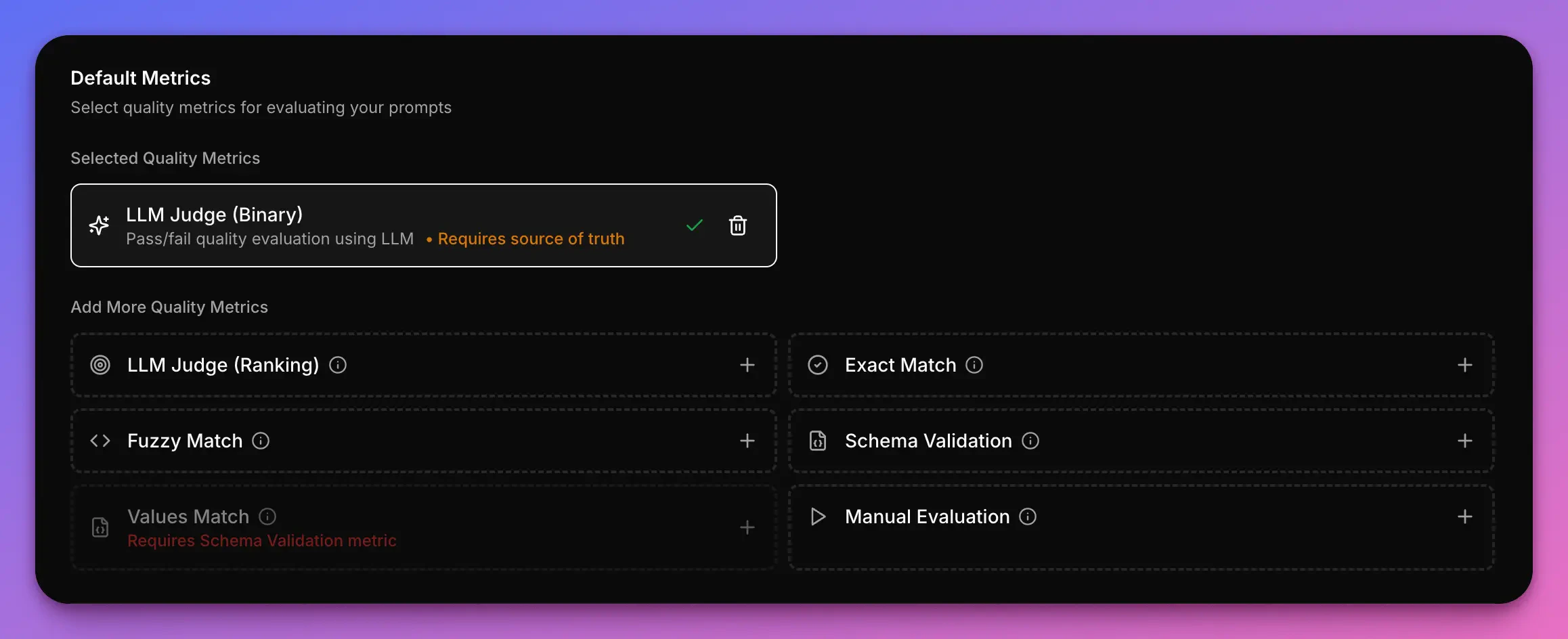
Part 3: Run the experiment
All that is left at this point, is running the actual experiment. If all the items in the checklist have a tick, it’s the time to click on Run and wait for the experiment to complete.Analyzing the results
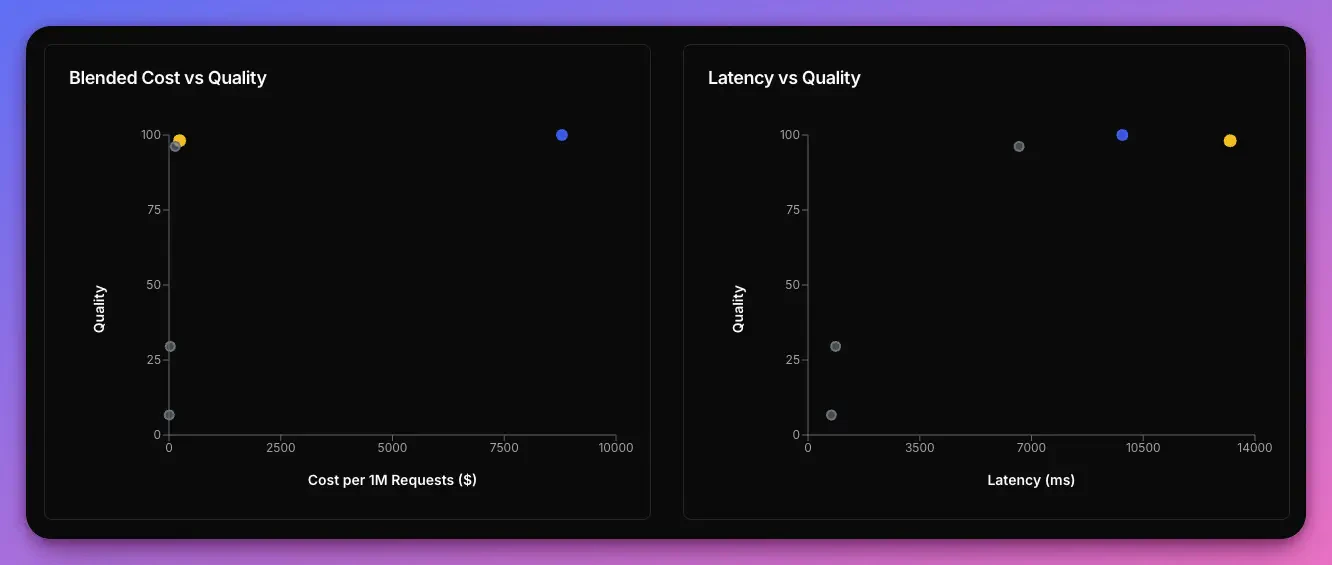
The Narev platform evaluated all variants against the baseline model. Results are based on 50 test prompts from the GSM8K math reasoning benchmarkKey insights from the benchmark
After running this benchmark, we discovered:- Quality-Cost tradeoff: DeepSeek v3.2 Speciale delivers 98.1% of baseline quality at only 2.7% of the cost—saving $8,552 per million tokens
- Latency considerations: While cheaper, DeepSeek is 34% slower than baseline. For latency-critical applications, this tradeoff matters
- Task alignment matters: Smaller models (Llama 3 70B, Ministral 3B) showed poor performance on math reasoning, demonstrating that model capabilities must match task complexity
A/B Tests -> Results -> Summary). Here we can see the best alternative for each optimization category: Quality, Cost and Latency.
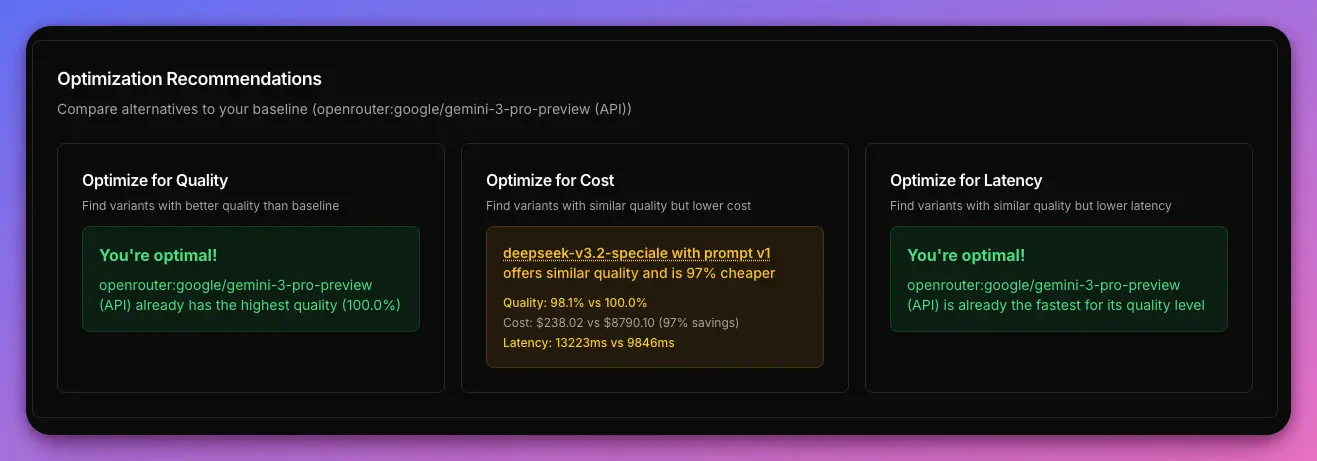
- Quality - We’re at the optimal spot (this means that there is no variant with a higher quality). Great source of truth. Truly a state of art model.
- Cost - We have one recommendation. It says that IF we were able to sacrifice 1.9% of quality, we COULD save 97% in token cost by choosing DeepSeek v3.2 Speciale
- Latency - For a model with this level of quality, there is no quicker model than that.
Deploying to production
Once you’ve identified your optimal model, deployment is straightforward:- In the Narev dashboard, set your chosen variant (e.g., DeepSeek v3.2 Speciale) as the production variant
- Continue using the same endpoint from Part 1:
https://www.narev.ai/api/applications/<YOUR_TEST_ID>/v1 - When you don’t specify a model in your requests, Narev automatically routes to your production variant
You can update your production variant anytime without changing your code. This enables seamless A/B testing and model
upgrades in production.
Resources
- Narev Platform Documentation
- Benchmark concepts
- Data Source Options
- Understanding evaluation metrics
- GSM8K Benchmark Dataset
Next steps
- Try with your own prompts and use case
- Experiment with different system prompts to optimize further
- Explore prompt optimization techniques