The Task: Extract the name of the author from a news article
Simple, right? Not quite. The author’s name hides in the HTML—usually in a photo credit or caption. The model needs to actually read and understand the page structure.Setup
- Get 100 articles from NewsAPI from October 13, 2025. Keywords: ‘Sydney’, ‘Australia’, ‘Melbourne’. Generic enough. The data included the author name and link to the original article.
- Scrape raw HTML of the 100 articles
- Clean HTML using trafilatura, which extracted just the main article content from the webpage while removing all the navigation, ads, and other clutter.
- Sanity check the HTML and filter out all the articles that don’t have an author (despite NewsAPI claiming otherwise)
- Ask models to identify the article author (using identical prompt)
- Evaluate the exact response (so rambling gets no point)
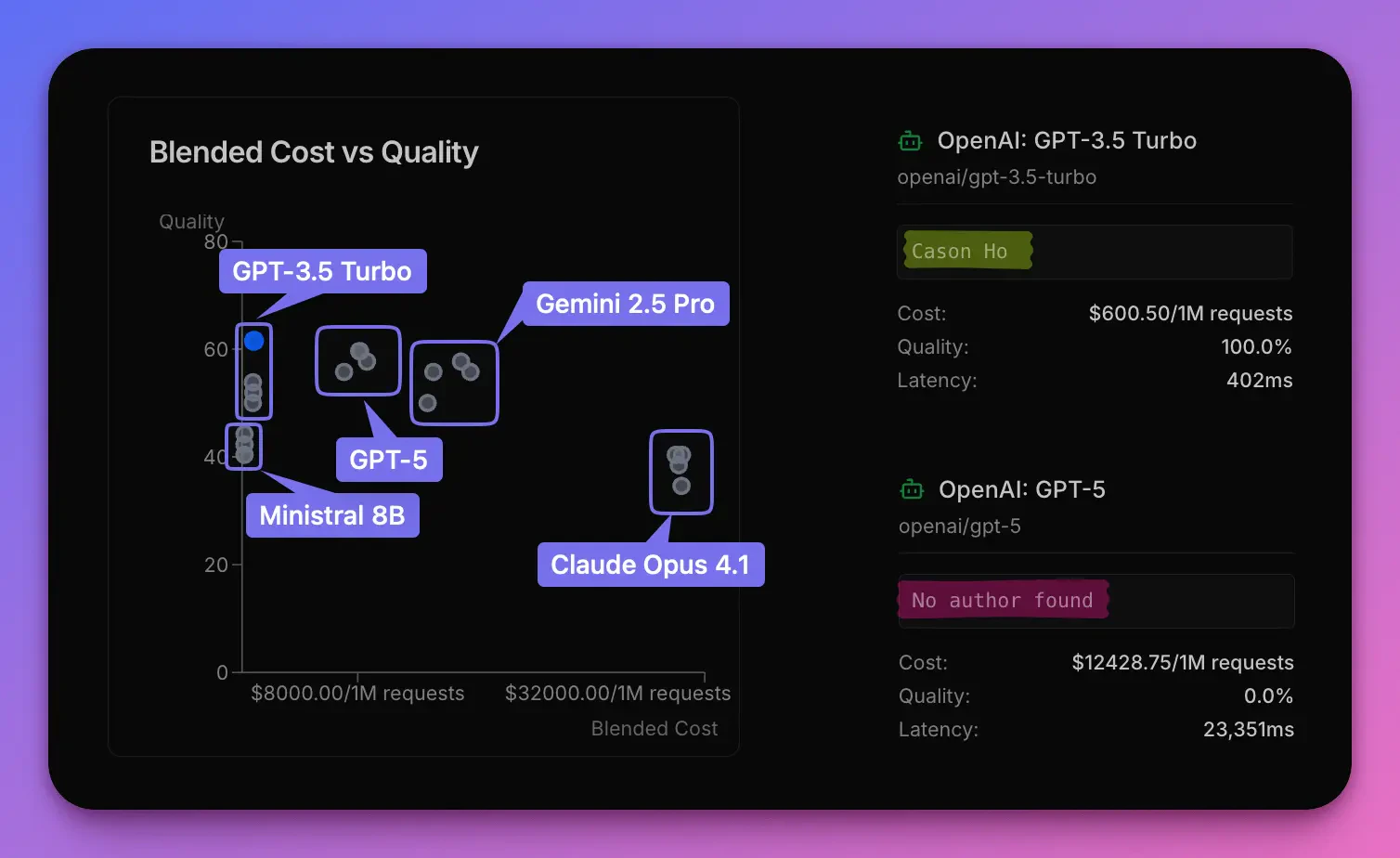
- Top 3 from MMLU: Claude Opus 4.1, Gemini 2.5 Pro, GPT-5
- Bottom 2 from MMLU: Ministral 8B, GPT-3.5 Turbo
The first result was… surprising
The 2023 model beat the 2025 flagship. By a lot. While costing 3% of the cost (30,390 per 1M requests).
Here is what happened
On a single example from this ABC News article on Tasmanian Saltmarsh restoration, Claude Opus 4.1 and Gemini 2.5 Pro responded:“Based on the HTML content, I cannot identify a specific author…”Meanwhile, GPT-3.5 Turbo just said:
“Madeleine Rojahn”(Which was correct.) The irony: Claude often did identify the correct author—it just buried the answer in verbose explanations about HTML structure, metadata analysis, and confidence levels. The system prompt asked for a simple format. Claude gave a dissertation. GPT-3.5 just followed instructions. The “smarter” models overthought it. The older model just did the job.
This is true
The test was rerun 3 times, same setup same models just repeated. The initial 61.5% for GPT-3.5 was on the higher end of the variance. The next three tests showed GPT-3.5 scoring 50.0%, 51.9%, and 53.8%—averaging ~54% across all runs.- GPT-3.5 remained comparable to GPT-5 and Gemini 2.5 Pro. Despite being two years older and scoring ~35 points lower on MMLU Pro.
- GPT-3.5 consistently beat Claude Opus 4.1. Every single time. The MMLU Pro champion couldn’t compete with the “bottom tier” model.
- Ministral 8B performed comparably to Claude Opus 4.1. Despite a 40-point gap on MMLU Pro (47% vs 87.9%), both “bottom tier” models scored within 6 percentage points on this task—suggesting the benchmark massively overestimated the performance difference.
Takeaway: leaderboards like MMLU don’t give a full picture
MMLU tests academic knowledge and reasoning. Our task tested practical instruction-following on messy real-world data. Completely different skill sets. And the benchmark didn’t predict which model would win. Your use case isn’t MMLU. Your use case needs its own leaderboard.Build your own benchmark in 5 minutes → Start testing