> ## Documentation Index
> Fetch the complete documentation index at: https://narev.ai/docs/llms.txt
> Use this file to discover all available pages before exploring further.
# Reduce LLM spend by switching models
> Case study: how switching from GPT-4 to gpt-oss-20b cut LLM inference costs by 99% while keeping 100% accuracy on a real product workload.
## The scenario
Imagine a support team using GPT-4 to automatically route customer emails to the right department.
Technical issues go to engineering, billing questions head to finance, and sales inquiries land with the sales team.
It's a straightforward task that works beautifully, except for one problem: the costs add up fast.
The question worth asking is: **do you really need the most expensive model on the market just to sort emails into categories?**
This is a very simple example illustrating the mechanism of A/B testing for LLMs. If you're after something more
complex, check the other guides.
## The hypothesis
email classification isn't exactly rocket science. You've got clear categories, predictable patterns, and relatively straightforward decision-making.
It's not like you're asking the model to write poetry or solve complex mathematical proofs.
So there's a good chance that a cheaper model might handle this task just as well, potentially saving on cost without sacrificing the quality of results.
But hunches aren't enough, let's test this hypothesis.
## Test configuration
This example shows a side-by-side comparison using the Narev Platform, testing five different models on the same set of customer emails with identical prompts.
The only variable? The model doing the classification.
This creates a clean way to see how each model performs on cost, speed, and accuracy.
### Variants tested
| Variant | Cost per 1M tokens (input/output) |
| ---------------- | --------------------------------- |
| GPT-4 (baseline) | $30/$60 |
| GPT-4.1 | $2/$8 |
| GPT-4.1 nano | $0.1/$0.4 |
| GPT-5 nano | $0.05/$0.4 |
| gpt-oss-20b | $0.03/$0.14 |
### What gets measured
The test tracks three critical metrics for each model:
* the **cost per request** (because that's the whole point)
* the **speed of classification** (nobody wants their customers waiting)
* the **accuracy of the routing decisions** (a cheap model that's wrong all the time isn't actually saving you money)
## Results
The results tell a fascinating story about the tradeoffs between different models.
GPT-4 serves as the baseline - 100% accurate but expensive.
The open source `gpt-oss-20b` emerges as the sweet spot, cutting costs by 99% while maintaining 100% accuracy. It matches GPT-4's perfect accuracy at a fraction of the cost, though it's slower. The 1-second slowdown is a tradeoff worth taking.
The ultra-cheap nano variants are tempting from a cost perspective, but the accuracy hit is too severe for production use.
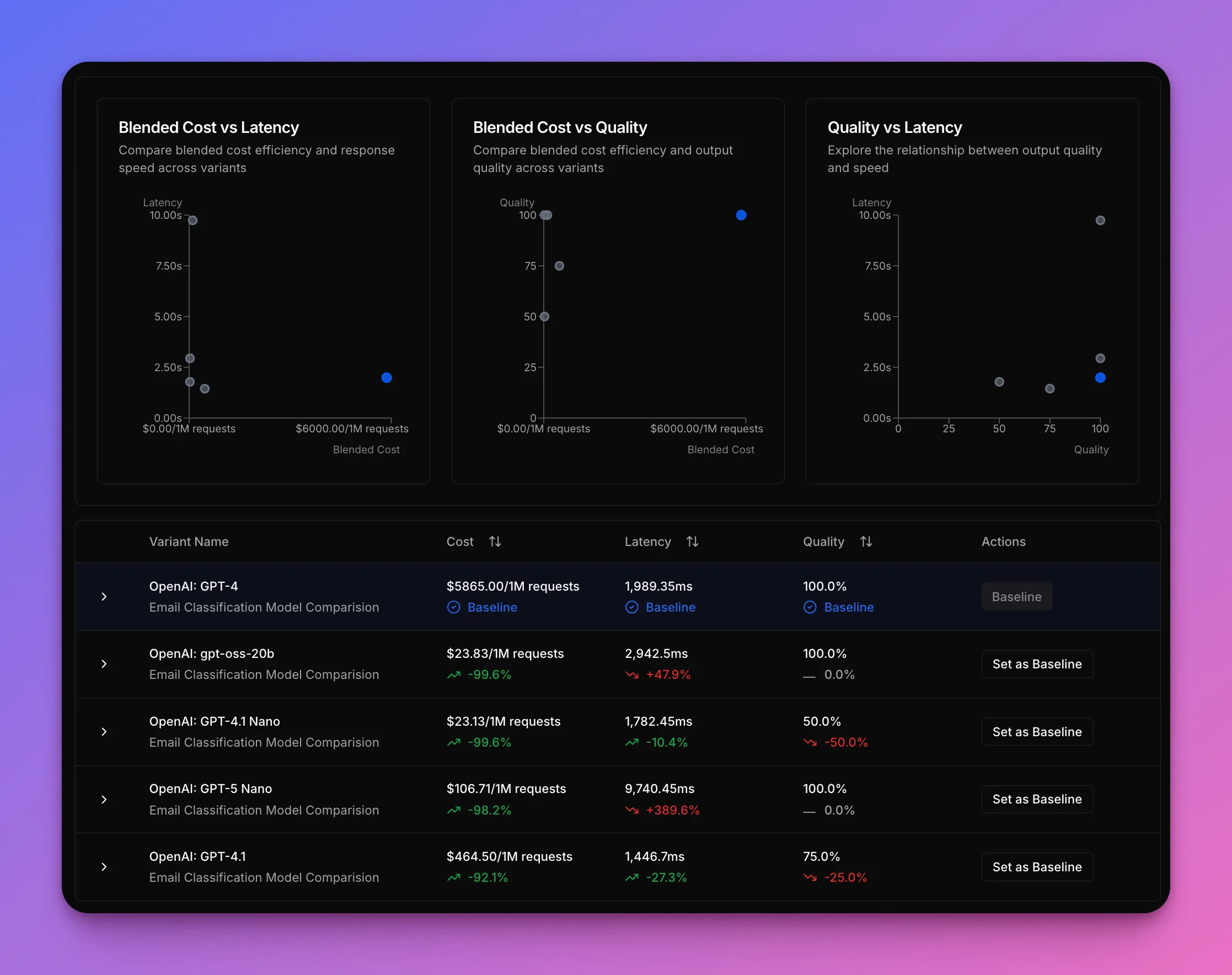 | Variant | Cost (avg) | Speed (avg) | Accuracy (total) |
| ------------ | -------------------- | -------------------- | ---------------- |
| **GPT-4** | **\$5,865/1M** | **1,989 ms** | **100%** |
| GPT-4.1 | \$464.50/1M (-92%) ✅ | 1,447 ms (faster) ✅ | 75% ⚠️ |
| GPT-4.1 nano | \$23.13/1M (-99%) ✅ | 1,782 ms (faster) ✅ | 50% ❌ |
| GPT-5 nano | \$106.71/1M (-98%) ✅ | 9,740 ms (slower) ❌ | 100% ✅ |
| gpt-oss-20b | \$23.83/1M (-99%) ✅ | 2,943 ms (slower) ⚠️ | 100% ✅ |
### Winner: `gpt-oss-20b`
The open source `gpt-oss-20b` wins out for this use case. It saves \$5,841 per million requests compared to GPT-4 (a 99% reduction), and crucially maintains 100% accuracy with no compromise on quality. While it's about 1 second slower per request than GPT-4, this tradeoff is well worth it - you're getting perfect classification at a fraction of the cost. Unlike the cheaper alternatives that sacrifice accuracy, gpt-oss-20b proves you don't have to choose between cost savings and reliable results.
## Example in action
Look at how the models handle a typical sales inquiry. This is the kind of email that should be an easy win: clear enterprise sales intent, multiple specific questions, and an explicit request for a demo.
**Subject:** Enterprise plan pricing\
**From:** [cto@fastgrowth.io](mailto:cto@fastgrowth.io)
Hi there,
A 200-person company is looking to upgrade. Could you send details about:
* Enterprise plan features
* Volume discounts
* Implementation timeline
* API rate limits
Please schedule a demo for next week.
Thanks,\
Mike Chen, CTO
**Should route to:** `Sales team`
### How each model did
| Model | Got it right? | Cost | Speed |
| --------------- | ------------- | -------------- | ---------- |
| GPT-4 | ✅ Yes | \$5,970/1M | 2,081 ms |
| GPT-4.1 | ✅ Yes | \$458/1M | 1,045 ms |
| GPT-4.1 nano | ✅ Yes | \$22.90/1M | 1,929 ms |
| GPT-5 nano | ✅ Yes | \$118.80/1M | 10,244 ms |
| **gpt-oss-20b** | ✅ **Yes** | **\$19.59/1M** | **881 ms** |
| Variant | Cost (avg) | Speed (avg) | Accuracy (total) |
| ------------ | -------------------- | -------------------- | ---------------- |
| **GPT-4** | **\$5,865/1M** | **1,989 ms** | **100%** |
| GPT-4.1 | \$464.50/1M (-92%) ✅ | 1,447 ms (faster) ✅ | 75% ⚠️ |
| GPT-4.1 nano | \$23.13/1M (-99%) ✅ | 1,782 ms (faster) ✅ | 50% ❌ |
| GPT-5 nano | \$106.71/1M (-98%) ✅ | 9,740 ms (slower) ❌ | 100% ✅ |
| gpt-oss-20b | \$23.83/1M (-99%) ✅ | 2,943 ms (slower) ⚠️ | 100% ✅ |
### Winner: `gpt-oss-20b`
The open source `gpt-oss-20b` wins out for this use case. It saves \$5,841 per million requests compared to GPT-4 (a 99% reduction), and crucially maintains 100% accuracy with no compromise on quality. While it's about 1 second slower per request than GPT-4, this tradeoff is well worth it - you're getting perfect classification at a fraction of the cost. Unlike the cheaper alternatives that sacrifice accuracy, gpt-oss-20b proves you don't have to choose between cost savings and reliable results.
## Example in action
Look at how the models handle a typical sales inquiry. This is the kind of email that should be an easy win: clear enterprise sales intent, multiple specific questions, and an explicit request for a demo.
**Subject:** Enterprise plan pricing\
**From:** [cto@fastgrowth.io](mailto:cto@fastgrowth.io)
Hi there,
A 200-person company is looking to upgrade. Could you send details about:
* Enterprise plan features
* Volume discounts
* Implementation timeline
* API rate limits
Please schedule a demo for next week.
Thanks,\
Mike Chen, CTO
**Should route to:** `Sales team`
### How each model did
| Model | Got it right? | Cost | Speed |
| --------------- | ------------- | -------------- | ---------- |
| GPT-4 | ✅ Yes | \$5,970/1M | 2,081 ms |
| GPT-4.1 | ✅ Yes | \$458/1M | 1,045 ms |
| GPT-4.1 nano | ✅ Yes | \$22.90/1M | 1,929 ms |
| GPT-5 nano | ✅ Yes | \$118.80/1M | 10,244 ms |
| **gpt-oss-20b** | ✅ **Yes** | **\$19.59/1M** | **881 ms** |
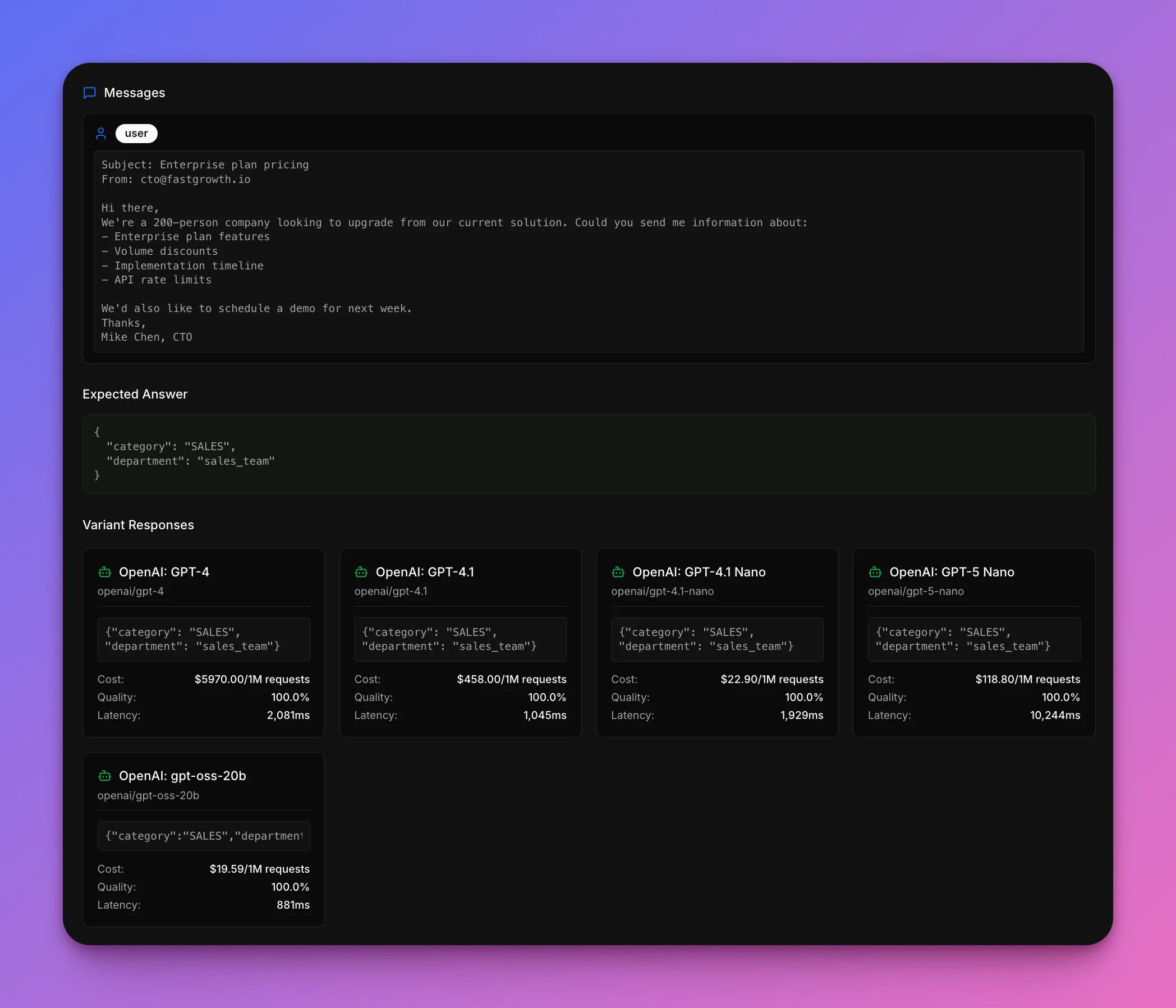 Good news: every model correctly routes this email to sales. This example shows that for straightforward cases (which make up the majority of customer emails), even the cheaper models can nail it. The differences between models show up more clearly in edge cases and ambiguous emails.
## What this shows
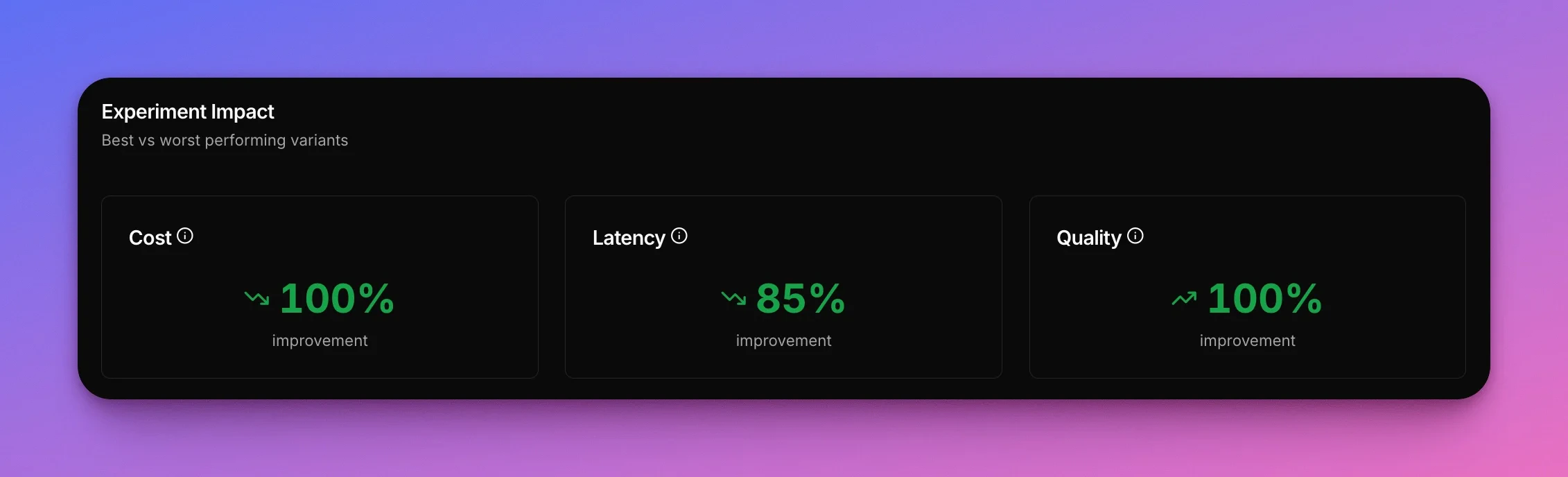
Task complexity should drive model choice, not default assumptions. For email classification, **`gpt-oss-20b` is the sweet spot**: **99% cheaper** than GPT-4 while maintaining **100% accuracy**.
You don't have to compromise between cost and quality. The tradeoff is **\~1 second slower** response times for **perfect classification at 0.4% of the cost**.
## The takeaway
Switching to **`gpt-oss-20b` saves $5,841 per million emails** while maintaining **100% accuracy**. Pay **$23.83** instead of **\$5,865** per million requests.
Good news: every model correctly routes this email to sales. This example shows that for straightforward cases (which make up the majority of customer emails), even the cheaper models can nail it. The differences between models show up more clearly in edge cases and ambiguous emails.
## What this shows
Task complexity should drive model choice, not default assumptions. For email classification, **`gpt-oss-20b` is the sweet spot**: **99% cheaper** than GPT-4 while maintaining **100% accuracy**.
You don't have to compromise between cost and quality. The tradeoff is **\~1 second slower** response times for **perfect classification at 0.4% of the cost**.
## The takeaway
Switching to **`gpt-oss-20b` saves $5,841 per million emails** while maintaining **100% accuracy**. Pay **$23.83** instead of **\$5,865** per million requests.
 If speed is critical and 75% accuracy is acceptable, GPT-4.1 is faster at \$464.50 per million. Otherwise, **`gpt-oss-20b` wins**: rock-bottom pricing with zero accuracy compromise.
***
Want to test which model works best for your use case? [Start testing for free →](https://narev.ai/login)
If speed is critical and 75% accuracy is acceptable, GPT-4.1 is faster at \$464.50 per million. Otherwise, **`gpt-oss-20b` wins**: rock-bottom pricing with zero accuracy compromise.
***
Want to test which model works best for your use case? [Start testing for free →](https://narev.ai/login)